
As these cloud service giants launch new generations of generative AI chips, competition in the field of generative AI is intensifying.
Metrans is verified distributor by manufacture and have more than 30000 kinds of electronic components in stock, we guarantee that we are sale only New and Original!
Generative AI large model, a battleground for military strategists
Technology giant Apple’s revenue from services reaches more than US$85 billion, accounting for 22% of total revenue. In the final analysis, large model applications represented by ChatGPT are also a type of service. Service functions such as large models are becoming a considerable source of business revenue growth for technology companies in the future. Therefore, generative AI has long been a battleground for military strategists.
According to research firm International Data Corp. (IDC), global enterprises will spend approximately $15.9 billion on generative AI solutions this year alone, and will spend approximately $35.5 billion in 2024. Global spending on generative AI is expected to reach $143.1 billion by 2027. IDC said that ICT companies spend approximately 7% on AI, and generative AI will account for 34% of overall AI spending in 2027. China’s spending on generative AI will have a compound annual growth rate of 87.5% from 2022 to 2027.
Moreover, industry users are generally very enthusiastic about the application and deployment of generative AI. IDC pointed out in the August 2023 "Gen AI ARC Survey" research report that among enterprises with more than 5,000 employees, 80% believe that GenAI (generative AI) will subvert their businesses in the next 18 months. business. Executives hope to see GenAI gains in customer experience, decision making and order speed by 2024. Many companies have included generative AI spending in their annual budgets.
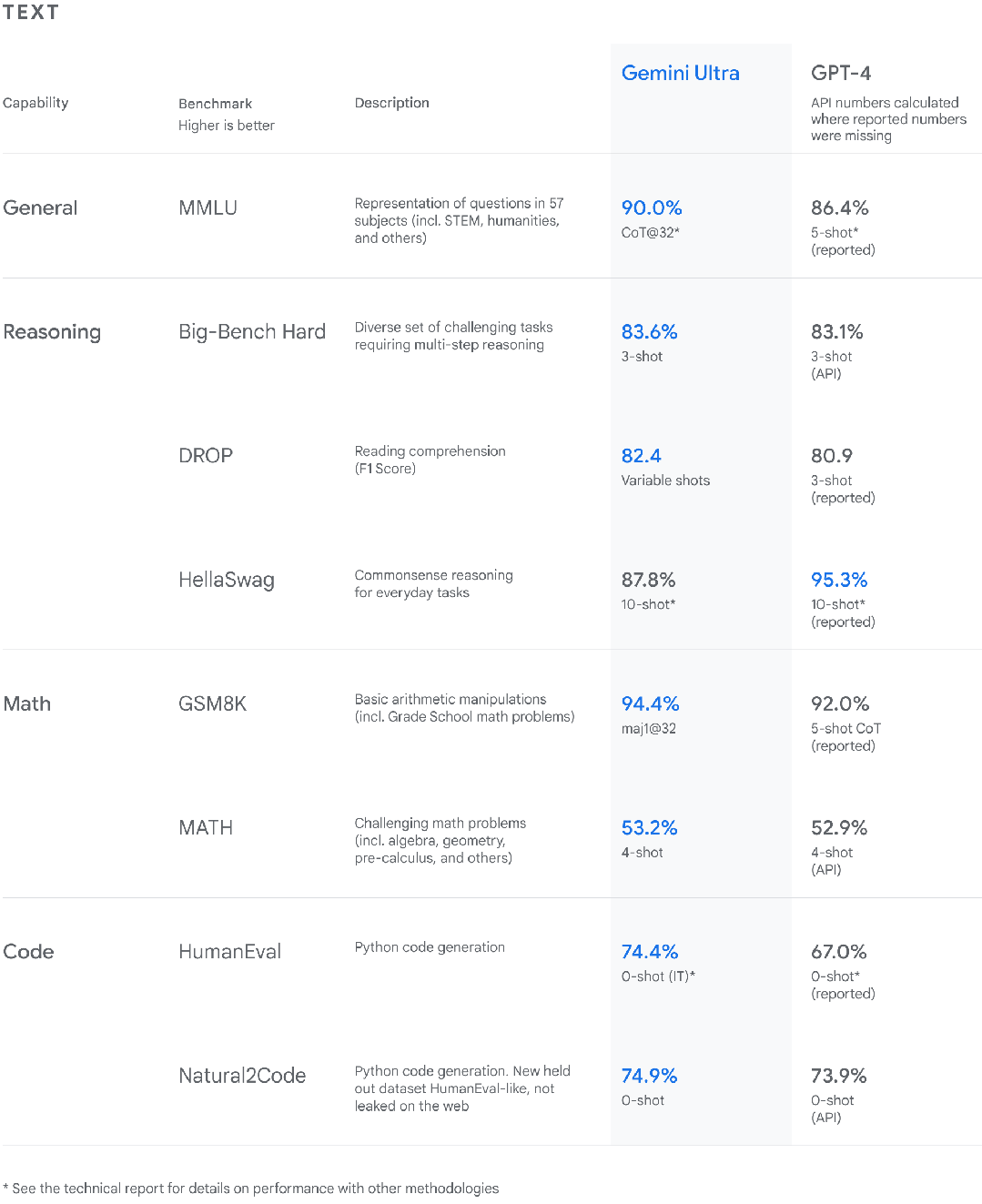
Under such market demand, cloud giants have all begun to lay out large models. Google recently launched Gemini, targeting GPT-4. Gemini is claimed by Google to have "performance superior to previous state-of-the-art models." As we all know, the most powerful large model today is GPT4. Gemini is built from the ground up to be multi-modal, meaning it can generalize and seamlessly understand, manipulate and combine different types of information, including text, code, audio, images and video. With a score of 90.0%, Gemini Ultra is the first model to surpass human experts in MMLU (Massive Multi-Task Language Understanding).
AWS also released the Titan Multimodal Foundation Model (FM), which incorporates Amazon’s 25 years of artificial intelligence (AI) and machine learning (ML) innovation. However, AWS's Titan model is a Vincentian image model. Its main audience is enterprises, such as advertising, e-commerce, and media and entertainment companies that can create studio-quality realistic images in large quantities at low cost, rather than OpenAI's As consumer-oriented as existing well-known image generators such as DALL-E.
In the field of generative AI, it is impossible to unlock all the value of generative AI with just a single large model. Therefore, after ChatGPT, there will inevitably be other high-performance large models on the market that will gain a foothold in the market. As for who will eventually be able to aspire to the Central Plains like ChatGPT, still needs to go through the test of the market.
Self-developed chips have become the mainstream in the development of large model enterprises
In the process of promoting the development of generative artificial intelligence applications, the underlying chip plays a crucial role. Considering the relatively high cost of X86 server CPUs and the staggering pricing of Nvidia Hopper H100 and H200 GPU accelerators and AMD Instinct MI300X and MI300A GPOU accelerators, it is more critical that these high-performance chips face insufficient supply. Therefore, self-developed chips have gradually become the mainstream way to promote the development of large model companies.
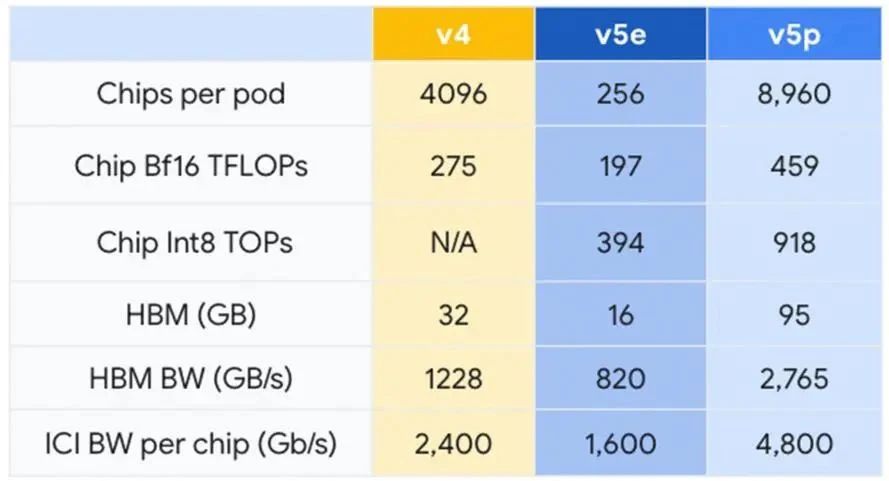
Among cloud service providers, Google is a senior chip player. Although Google's first-generation TPU chip was released at the Google I/O Developer Conference in 2016, its journey of self-developed chips began ten years ago. Interested readers can read "Google's Self-Developed Chips" Chip Empire". Its latest TPU chip, TPU v5p, has more than 2 times the FLOPS and more than 3 times the high-bandwidth memory (HBM) compared to TPU v4, with a total capacity of 95GB. Google combines these TPU v5p into Pods. Each TPU v5p Pod is composed of 8,960 chips and is connected through Google's highest bandwidth inter-chip interconnect (ICI), using a 3D torus topology with a per-chip rate of 4,800 Gbps. Google claims that TPU v5p can train large LLM models 2.8 times faster than the previous generation TPU v4. Google's latest Gemini large model uses TPU for training and serving, and Google said that Gemini, a custom chip using TPU, runs significantly faster than earlier, smaller and less powerful models.
 AWS also recently released Trainium 2, which is designed for high-performance deep learning training. The Trainium 2 chip can train base models with hundreds of billions to trillions of parameters for optimization. Each Trainium accelerator contains two second-generation NeuronCores built specifically for deep learning algorithms, using NeuronLink, an in-instance, ultra-high-speed, non-blocking interconnect technology. The Trainium 2 accelerator has 32GB of high-bandwidth memory, providing up to 190 TFLOPS of FP16/BF16 computing power, which is 4 times faster than the Trainium 1 chip training speed. And can be deployed in EC2 UltraClusters with up to 100,000 chips, allowing basic model (FM) and large language model (LLM) training to take very little time while increasing energy efficiency by up to 2 times.
AWS also recently released Trainium 2, which is designed for high-performance deep learning training. The Trainium 2 chip can train base models with hundreds of billions to trillions of parameters for optimization. Each Trainium accelerator contains two second-generation NeuronCores built specifically for deep learning algorithms, using NeuronLink, an in-instance, ultra-high-speed, non-blocking interconnect technology. The Trainium 2 accelerator has 32GB of high-bandwidth memory, providing up to 190 TFLOPS of FP16/BF16 computing power, which is 4 times faster than the Trainium 1 chip training speed. And can be deployed in EC2 UltraClusters with up to 100,000 chips, allowing basic model (FM) and large language model (LLM) training to take very little time while increasing energy efficiency by up to 2 times.
Compared with Google and AWS, Microsoft can be said to have started late in the field of self-developed chips, but its momentum is fierce. Microsoft's self-developed Maia 100 chip is based on TSMC's 5-nanometer process and contains a total of 105 billion transistors. Judging from public data, Microsoft's chip is the largest AI chip so far. Maia 100's performance under MXInt8 is 1600 TFLOPS, and under MXFP4 it records a computing speed of 3200 TFLOPS. Judging from these FLOPS, this chip completely crushes Google's TPU v5 (Viperfish) and Amazon's Trainium/Inferentia2 chips. Compared with Nvidia's H100 and AMD's MI300X, the gap between Microsoft Maia 100 is not far. However, in terms of memory bandwidth, the specification of Microsoft Maia 100 is 1.6TB/s memory bandwidth, which is higher than Trainium/Inferentia2, but inferior to TPUv5. As for the reason, according to semianalysis, the reason why Microsoft has such "error" ”, entirely because this chip was designed before the LLM craze happened. In terms of chip interconnect, similar to what Google does with its TPUv5 and proprietary ICI network, Microsoft has its own built-in RDMA Ethernet IO with a transmission speed of 4.8Tbps in each chip.
There are many rumors in the market that OpenAI, the developer of ChatGPT, is also considering developing its own chips and has recruited many industry leaders. According to this development trend, it is possible that large model companies in the future will adopt a self-research strategy.
The reason behind: To lower the price? GPU replacement? Or is it just an alternative?
So, what are these leading cloud manufacturers that are entering large-scale models doing with their self-developed chips?
As we all know, the prices of chips currently on the market that can be used for large generative AI model training are generally very high, so are these manufacturers doing their own research to lower prices? It is reported that after Google uses TPU, it does not have to pay 70% of the profits to Nvidia. Or will it completely replace third-party GPUs or other AI accelerator chips? Or is it just a backup? In this regard, experts from different fields in the industry have expressed their opinions.
Han Yinhe, a researcher at the Institute of Computing Technology of the Chinese Academy of Sciences, believes that their main purpose is to use chips to enhance their core competitiveness in large models or cloud computing services, not just to reduce costs. He also mentioned that OpenAI also revealed the news of self-developed AI chips. They will definitely make certain customizations in large model training and inference to enhance their company's core competitiveness in large model research and development. Such customized chips usually have certain advantages in their own business, but lack the versatility of GPUs.
As far as the current situation is concerned, although these manufacturers have gradually released self-developed chips, they are still dependent on GPUs in the short term. As Amin Vahdat, vice president of Google Cloud AI, said, Gemini will run on both GPU and TPU. Regarding this phenomenon, Huang Chaobo, founder and CEO of Moxiang Technology, pointed out that Google still uses GPUs even though it develops its own TPU. This phenomenon is actually easy to understand. Today's large models are still undergoing continuous iteration. At the beginning, some ideas are quickly verified through more friendly programming on the GPU platform. After the business scale increases, it is a natural way to optimize cost or performance through TPU. In Huang Chaobo's view, the purpose of these manufacturers' self-developed chips is to have both. In the short term, it is to lower prices, and in the long term, it is substitution. Nvidia will remain one of the hottest chip companies for a long time to come, but its profit margins will slowly return to a normal range.
Industry investor Jasper believes that Nvidia GPUs still have high barriers to ecology, ease of use and versatility, and are still irreplaceable in the short term. Moreover, there is still a certain gap between TPU and NV in terms of chip-level performance and software ecology, especially in general tasks. Many third-party customers still have difficulties switching from Nvidia to TPU. However, Google's TPU + optical interconnection + system + large model Infra is actually more advantageous at the system level.
Roland, an expert in the artificial intelligence and chip industry, has a similar view to Jasper. He told Semiconductor Industry Watch that in the foreseeable future, Nvidia’s GPUs will be the standard solution for cloud artificial intelligence training and deployment. The reason is that the cloud artificial intelligence software and hardware technology stacks in the past ten years have been based on Nvidia solutions. The relevant deployment solutions and codes have been deeply ingrained in the major cloud manufacturers, so there is a risk of switching to another self-developed solution in the next one or two years. great.
But Roland further pointed out, “Such as Google Gemini, which runs on TPU (self-developed chip) and GPU at the same time, is largely to ensure that there is an alternative if the self-developed chip solution encounters unexpected problems. The problem can also be switched to Nvidia's GPU, and vice versa. In the future, self-developed solutions can only slowly replace Nvidia. When self-developed solutions become mature enough, they are expected to increasingly replace Nvidia. But even in the latest Optimistically, complete replacement is unlikely.”
Therefore, in Roland's view, manufacturers' self-developed chips are a second source solution. The purpose is not only to lower the price (in fact, it may not be able to lower the price too much), but also to keep the core technology in their own hands. It is easier for you to formulate a future roadmap without being overly dependent on certain suppliers. The advantage of this is: on the one hand, if the mainstream solutions are out of stock or unavailable for other reasons, there are self-developed solutions to ensure supply chain security; on the other hand, when new technologies emerge, current mainstream solution suppliers When you are unable to support or unwilling to support, you can be able to use your own plan to support it.
When talking about the cost-effectiveness of self-developed chips by cloud manufacturers, Han Yinhe said that this is actually an issue that will take time to be verified. Judging from the experience of the development of the semiconductor industry, in chip types such as AI chips that have large quantities and form an ecosystem, the result of long-term competition is often that the winner takes all. This is a cruel reality. When looking at chips, we not only need to look at the final high manufacturing cost, but also the large amount of manpower and time costs invested in front-end R&D and design. If it is a company with chips as its main product and accounting unit, it is difficult for a single company to support a single company. The cost of large chip manufacturers. Of course, Google and Microsoft may use the cloud services or large model capabilities they finally provide as their calculation unit. If the chip can provide assistance to their core competitiveness, this account may be justified.
Investor Jasper also analyzed that Nvidia's comprehensive gross profit in 2023Q3 is 73.95%, and the gross profit market for high-end chips is expected to be even higher. Such a high gross profit is a possible cost saving for self-developed chips. The actual cost savings must also take into account the research and development costs of self-developed chips and the entire set of software and hardware costs. However, due to the huge training costs of multi-modal large models and the massive application scenarios in the future, the cost-effectiveness of self-developed chips by cloud vendors is still worth looking forward to.
Dedicated generative AI chips are an inevitable trend in the development of large models in the future.
"When we evaluate the comprehensive capabilities of a computing chip, we usually need to pay attention to two parameters: performance and versatility. AI models have been iterating rapidly. Because of versatility, TPU has not been as easy to use as GPU." Huang Chaobo pointed out, "But the situation is changing. Since the Transformer model, Transformer has a tendency to unify AI models. Although some new underlying algorithms have been proposed, the core operators have not changed much compared to Transformer. In other words, with the underlying AI model, Algorithm iterations slow down, and dedicated chips can keep up with this iteration rhythm. In this case, compared to GPUs, dedicated AI chips such as TPUs have no disadvantage in terms of versatility, and are more efficient in performance than GPUs. "
He further emphasized: "If we elaborate on this matter from a technical perspective, the current general flexibility of NVIDIA GPUs just matches the general flexibility required for upper-layer large model algorithm iteration. But at the same time, we have also seen that the entire The industry is very optimistic about the breakthrough of AGI, and the underlying algorithm structure is gradually settling. In this case, self-developed dedicated AI acceleration processors will be an inevitable trend in the future."
Considering that algorithm iteration is still relatively fast. Huang Chaobo emphasized that in the next five years, AI processors that can shine should be like this: more specialized and more efficient than GPUs, but more general and less efficient than current dedicated AI chips. In terms of performance, and reach a new balance in terms of versatility.
As various dedicated generative AI chips come out one after another, the industry can't help but ask, will these cloud vendors become another strong rival of Nvidia GPUs? In this regard, Han Yinhe said that he did not think it would happen in the short term. He pointed out that whether it is TPU or the AI chips being developed by Microsoft and others, they mainly meet their own business needs and are not supplied to external parties. If you want to supply external products, you need to form a mature ecosystem, which includes software, tools, developers, etc. In this regard, it is very difficult to surpass NVIDIA, and it cannot be solved by a single performance lead. In addition, there is the issue of stable supply chain partnerships. Large-scale chip mass production requires stable supply chain support, which is also a challenge for cloud manufacturers.
Investor Jasper said: "Historically, Nvidia is very much like Cisco around 2000. At that time, Cisco also integrated software and hardware, ultra-high performance, and a strong moat, so it had high barriers and gross profits, and business growth. and market value are growing very rapidly. However, as downstream customer applications continue to increase, eventually servers and network equipment are rapidly self-developed. Will Cisco's yesterday become Nvidia's tomorrow?"
Conclusion
In terms of "self-sufficiency" in self-developed chips, these cloud vendors have already found a successful path. AWS' Graviton chip has iterated to its fourth generation and is developing rapidly in the server field. The same is true for Google's TPU chips. TPU chips have long been the core of Google's artificial intelligence business. TPU chips provide services for billions of users such as search, YouTube, Gmail, Google Maps, Google Play and Android. Now they are transferring this successful experience to the field of generative AI.
With the intervention of these cloud vendors, the research and development of large-scale models and dedicated AI chips will be promoted, and the innovation and application of these technologies will be accelerated. The chips specially designed for generative AI launched by these manufacturers may make the application of generative AI technology more economical and feasible.


